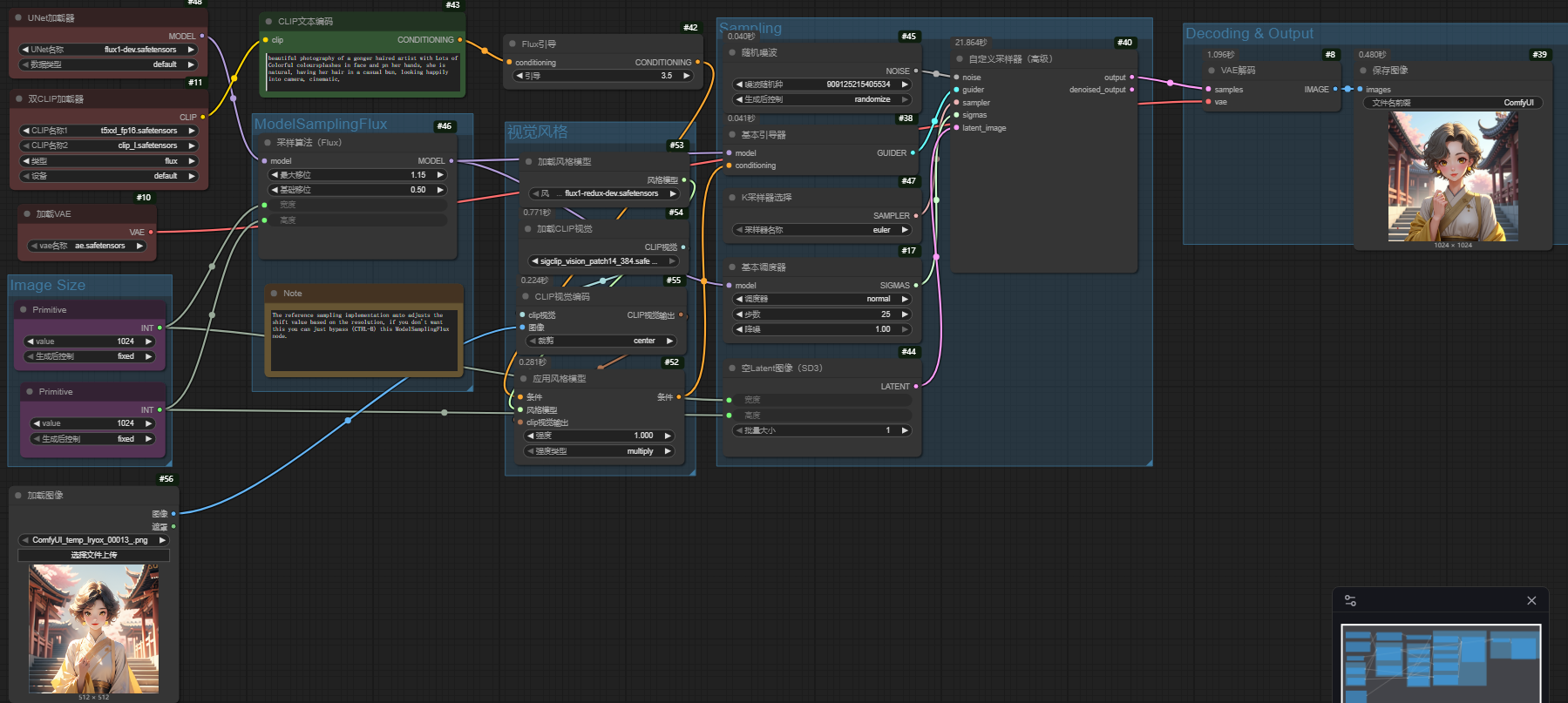
CLIP Vision Encode / CLIP视觉编码
节点功能:该节点是一个 图像编码节点,使用的是 CLIP Vision 模型 —— 一种能“理解图片”的 AI 模型。你把一张图像输入进来,它会把这张图像转成一种“向量”形式(称为 图像特征编码),供后续模型使用,比如:IPAdapter 图像风格控制;检索相似图像;与文本提示配合做图像引导(如图文混合生成);在多模态模型中对图像内容做特征提取。
CLIP Vision Encode - 节点参数说明
| 输入参数 | |
| clip_vision | 图像编码模型,一般来自 Load CLIPVision 节点输出。提供 CLIP 模型的视觉部分。 |
| image | 输入图像,用于提取视觉特征。 |
| 输出参数 | |
| CLIP_VISION_OUTPUT | 图像在 CLIP 模型中的编码特征结果。 |
| 控件参数 | |
| crop | 图像裁剪方式。可选值包括: - center:裁剪中心区域用于特征提取; - none:不裁剪,使用整张图像。 |
下图为CLIP视觉编码的节点使用
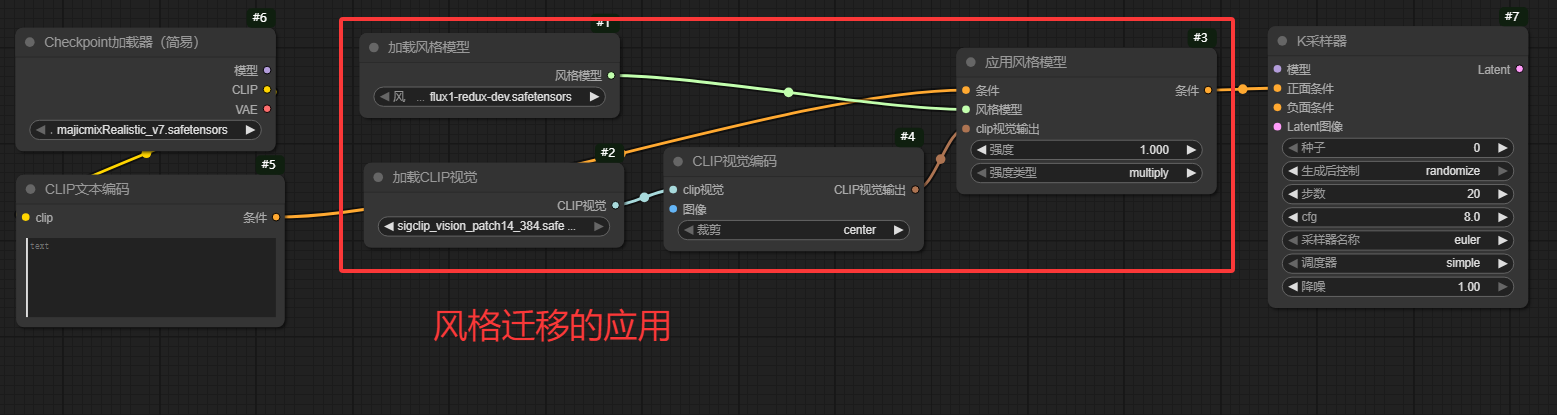
下图的工作流是flux官方的文生图加入redux的示例,该节点在工作流中主要负责提取图片的视觉特征信息