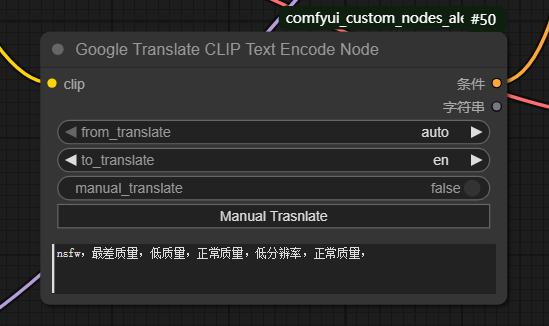
Google Translate CLIP Text Encode Node
节点功能:使用 Google 翻译对 CLIP 模型中的文本进行翻译和编码,以便 AI 艺术家处理多语言输入。
Google Translate CLIP Text Encode Node - 节点参数说明
| 输入参数 | |
| clip | clip模型实例 |
| 输出参数 | |
| CONDITIONING | 此输出提供了 CLIP 模型在对翻译文本进行编码后生成的条件数据。它包括编码后的词元和汇总输出,这些数据对于将翻译文本集成到使用 CLIP 进行文本到图像或其他多模态任务的 AI 模型中至关重要。 |
| STRING | 此输出将翻译后的文本以字符串形式返回。这使用户能够查看翻译结果,并将翻译后的文本用于进一步处理或显示用途。 |
| 控件参数 | |
| from_translate | 此参数指定待翻译文本的源语言。您可以将其设置为“auto”以自动检测语言,或从支持的语言列表中选择任何特定的语言代码。默认值为“auto”。此参数对于确保正确识别文本并从相应的语言进行翻译至关重要。 |
| to_translate | 此参数定义文本要翻译成的目标语言。它必须设置为受支持的语言代码之一,默认值为“en”(英语)。此参数决定翻译输出的语言,这对于需要特定语言文本的用户至关重要。 |
| manual_translate | 此布尔参数指示翻译是手动执行还是自动执行。如果设置为 false True,则文本将不进行翻译,直接使用原文。如果设置为 true False,则文本将使用 Google 翻译进行翻译。默认值为 false False。如果文本已是目标语言,则用户可以使用此参数跳过翻译步骤。 |
| text | 此参数为字符串输入,包含待翻译和编码的文本提示。它支持多行输入,并提供占位符“输入提示”以引导用户。这是将要进行翻译和编码的主要文本,因此是节点功能的关键输入。 |
介绍
该GoogleTranslateCLIPTextEncodeNode节点旨在利用谷歌翻译简化文本提示的翻译,并将翻译后的文本编码为适用于 CLIP(对比语言-图像预训练)模型的格式。对于需要处理多语言文本输入的 AI 艺术家而言,此节点尤为有用,因为它可以确保提示信息被准确翻译和编码,以便后续在 AI 模型中进行处理。通过利用谷歌翻译,该节点可以自动检测源语言并将其翻译成目标语言,从而简化处理各种语言输入的过程。翻译后的文本随后会被分词并使用 CLIP 模型进行编码,最终输出条件数据和翻译后的文本。此过程确保文本不仅被翻译,而且还能与使用 CLIP 进行文本转图像或其他多模态任务的 AI 模型集成。
用例